Файл robots.txt создается специально для поисковых ботов, чтобы они знали куда идти и индексировать, а куда вход запрещен. Если неправильно его настроить, вы можете вообще не попасть в поиск или попасть только у некоторых.
Чтобы не было проблем с продвижением и индексацией статей, вам нужно знать, как создать robots txt для всех поисковиков. Это занимает мало времени, но после этого вы будете спокойны.
Некоторые вебмастера и вовсе обходятся без него (в основном, конечно, по незнанию). С одной стороны это разумно для новичков – так вы точно не закроете от поисковых роботов нужную информацию. Но с другой стороны, этот небольшой файл защищает личные данные и не дает спам-ботам просматривать информацию на сайте.
Начинающим блоггерам я рекомендую использовать шаблоны. К примеру, шаблон robots txt для WordPress Скачать . Скачайте и исправьте «ваш_сайт..

Расшифровка значений:
- User-agent: * — вы обращаетесь сразу ко всем поисковым системам, Yandex — только к Яндексу.
- Disallow: перечислены папки и файлы, которые запрещены для индексации
- Host – пропишите название вашего сайта без www.
- Sitemap: ссылка на XML-карту сайта.
Файл поместите в корневую директорию сайта с помощью Filezilla или через сайт хостера. Скидывайте в главную директорию, чтобы он был доступен по ссылке: ваш_сайт.ру/robots.txt
Он подойдет только для тех, у кого стоят ЧПУ (ссылки прописаны словами, а не в виде p=333). Достаточно зайти в Настройки – Постоянные ссылки, выбрать нижний вариант и в поле прописать /%postname%
Некоторые предпочитают создавать этот файл самостоятельно:
Для начала создайте блокнот на компьютере и назовите его robots (не используйте верхний регистр). В конце настроек его размер не должен быть больше 500 кб.
User-agent – название поисковой системы (Yandex, Googlebot, StackRambler). Если вы хотите обратиться сразу ко всем, поставьте звездочку *

А затем укажите страницы или папки, которые нельзя индексировать этому роботу с помощью Disallow :

Сначала перечислены три директории, а потом конкретный файл.
Чтобы разрешить индексировать все и всем, нужно прописать:
User-agent: *
Disallow:
Настройка robots.txt для Яндекс и Google
Для Яндекса обязательно нужно добавить директиву host, чтобы не появлялось дублей страниц. Это слово понимает только бот от Яндекса, так что прописывайте указания для него отдельно.

Для Google нет никаких дополнений. Единственное, нужно знать, как к нему обращаться. В разделе User-agent нужно писать:
- Googlebot;
- Googlebot-Image – если ограничиваете индексацию изображений;
- Googlebot-Mobile — для мобильной версии сайта.
Как проверить работоспособность файла robots.txt
Это можно сделать в разделе «Инструменты для веб-мастеров» от поисковика Google или на сайте Яндекс.Вебмастер в разделе Проверить robots.txt.
Если будут ошибки, исправьте их и проверьте еще раз. Добейтесь хорошего результата, затем не забудьте скопировать правильный код в robots.txt и залить его на сайт.
Теперь вы имеете представление, как создать robots.txt для всех поисковиков. Новичкам рекомендую использовать готовый файл, подставив название своего сайта.
Время чтения: 7 минут(ы)
Почти каждый проект, который приходит к нам на аудит либо продвижение, имеет некорректный файл robots.txt, а часто он вовсе отсутствует. Так происходит, потому что при создании файла все руководствуются своей фантазией, а не правилами. Давайте разберем, как правильно составить этот файл, чтобы поисковые роботы эффективно с ним работали.
Зачем нужна настройка robots.txt?
Robots.txt - это файл, размещенный в корневом каталоге сайта, который сообщает роботам поисковых систем, к каким разделам и страницам сайта они могут получить доступ, а к каким нет.
Настройка robots.txt - важная часть в выдаче поисковых систем, правильно настроенный robots также увеличивает производительность сайта. Отсутствие Robots.txt не остановит поисковые системы сканировать и индексировать сайт, но если этого файла у вас нет, у вас могут появиться две проблемы:
Поисковый робот будет считывать весь сайт, что «подорвет» краулинговый бюджет. Краулинговый бюджет - это число страниц, которые поисковый робот способен обойти за определенный промежуток времени.
Без файла robots, поисковик получит доступ к черновым и скрытым страницам, к сотням страниц, используемых для администрирования CMS. Он их проиндексирует, а когда дело дойдет до нужных страниц, на которых представлен непосредственный контент для посетителей, «закончится» краулинговый бюджет.
В индекс может попасть страница входа на сайт, другие ресурсы администратора, поэтому злоумышленник сможет легко их отследить и провести ddos атаку или взломать сайт.
Как поисковые роботы видят сайт с robots.txt и без него:

Синтаксис robots.txt
Прежде чем начать разбирать синтаксис и настраивать robots.txt, посмотрим на то, как должен выглядеть «идеальный файл»:

Но не стоит сразу же его применять. Для каждого сайта чаще всего необходимы свои настройки, так как у всех у нас разная структура сайта, разные CMS. Разберем каждую директиву по порядку.
User-agent
User-agent - определяет поискового робота, который обязан следовать описанным в файле инструкциям. Если необходимо обратиться сразу ко всем, то используется значок *. Также можно обратиться к определенному поисковому роботу. Например, Яндекс и Google:

С помощью этой директивы, робот понимает какие файлы и папки индексировать запрещено. Если вы хотите, чтобы весь ваш сайт был открыт для индексации оставьте значение Disallow пустым. Чтобы скрыть весь контент на сайте после Disallow поставьте “/”.
Мы можем запретить доступ к определенной папке, файлу или расширению файла. В нашем примере, мы обращаемся ко всем поисковым роботам, закрываем доступ к папке bitrix, search и расширению pdf.

Allow
Allow принудительно открывает для индексирования страницы и разделы сайта. На примере выше мы обращаемся к поисковому роботу Google, закрываем доступ к папке bitrix, search и расширению pdf. Но в папке bitrix мы принудительно открываем 3 папки для индексирования: components, js, tools.

Host - зеркало сайта
Зеркало сайта - это дубликат основного сайта. Зеркала используются для самых разных целей: смена адреса, безопасность, снижение нагрузки на сервер и т. д.
Host - одно из самых важных правил. Если прописано данное правило, то робот поймет, какое из зеркал сайта стоит учитывать для индексации. Данная директива необходима для роботов Яндекса и Mail.ru. Другие роботы это правило будут игнорировать. Host прописывается только один раз!
Для протоколов «https://» и «http://», синтаксис в файле robots.txt будет разный.
Sitemap - карта сайта
Карта сайта - это форма навигации по сайту, которая используется для информирования поисковых систем о новых страницах. С помощью директивы sitemap, мы «насильно» показываем роботу, где расположена карта.

Символы в robots.txt
Символы, применяемые в файле: «/, *, $, #».

Проверка работоспособности после настройки robots.txt
После того как вы разместили Robots.txt на своем сайте, вам необходимо добавить и проверить его в вебмастере Яндекса и Google.
Проверка Яндекса:
- Перейдите по ссылке .
- Выберите: Настройка индексирования - Анализ robots.txt.
Проверка Google:
- Перейдите по ссылке .
- Выберите: Сканирование - Инструмент проверки файла robots.txt.
Таким образом вы сможете проверить свой robots.txt на ошибки и внести необходимые настройки, если потребуется.
- Содержимое файла необходимо писать прописными буквами.
- В директиве Disallow нужно указывать только один файл или директорию.
- Строка «User-agent» не должна быть пустой.
- User-agent всегда должна идти перед Disallow.
- Не стоит забывать прописывать слэш, если нужно запретить индексацию директории.
- Перед загрузкой файла на сервер, обязательно нужно проверить его на наличие синтаксических и орфографических ошибок.
Успехов вам!
Видеообзор 3 методов создания и настройки файла Robots.txt
Виды роботов Яндекса
- Yandex/1.01.001 (compatible; Win16; I) - основной индексирующий робот
- Yandex/1.01.001 (compatible; Win16; P) - индексатор картинок
- Yandex/1.01.001 (compatible; Win16; H) - робот, определяющий зеркала сайтов
- Yandex/1.02.000 (compatible; Win16; F) - робот, индексирующий пиктограммы сайтов (favicons)
- Yandex/1.03.003 (compatible; Win16; D) - робот, обращающийся к странице при добавлении ее через форму «Добавить URL»
- Yandex/1.03.000 (compatible; Win16; M) - робот, обращающийся при открытии страницы по ссылке «Найденные слова»
- YaDirectBot/1.0 (compatible; Win16; I) - робот, индексирующий страницы сайтов, участвующих в Рекламной сети Яндекса
- YandexBlog/0.99.101 (compatible; DOS3.30,B) – робот, индексирующий xml-файлы для поиска по блогам.
- YandexSomething/1.0 – робот, индексирующий новостные потоки партнеров Яндекс-Новостей.
- Bond, James Bond (version 0.07) - робот, заходящий на сайты из подсети Яндекса. Официально никогда не упоминался. Ходит выборочно по страницам. Referer не передает. Картинки не загружает. Судя по повадкам, робот занимается проверкой сайтов на нарушения – клоакинг и пр.
IP-адреса роботов Яндекса
IP-адресов, с которых «ходит» робот Яндекса, много, и они могут меняться. Список адресов не разглашается.
Кроме роботов у Яндекса есть несколько агентов-«простукивалок», которые определяют, доступен ли в данный момент сайт или документ, на который стоит ссылка в соответствующем сервисе.
- Yandex/2.01.000 (compatible; Win16; Dyatel; C) - «простукивалка» Яндекс.Каталога. Если сайт недоступен в течение нескольких дней, он снимается с публикации. Как только сайт начинает отвечать, он автоматически появляется в Каталоге.
- Yandex/2.01.000 (compatible; Win16; Dyatel; Z) - «простукивалка» Яндекс.Закладок. Ссылки на недоступные сайты помечаются серым цветом.
- Yandex/2.01.000 (compatible; Win16; Dyatel; D) - «простукивалка» Яндекс.Директа. Она проверяет корректность ссылок из объявлений перед модерацией. Никаких автоматических действий не предпринимается.
- Yandex/2.01.000 (compatible; Win16; Dyatel; N) - «простукивалка» Яндекс.Новостей. Она формирует отчет для контент-менеджера, который оценивает масштаб проблем и, при необходимости, связывается с партнером.
Директива Host
Во избежания возникновения проблем с зеркалами сайта рекомендуется использовать директиву «Host». Директива «Host» указывает роботу Яндекса на главное зеркало данного сайта. С директивой «Disallow» никак не связана.
User-agent: Yandex
Disallow: /cgi-bin
Host: www.site.ru
User-agent: Yandex
Disallow: /cgi-bin
Host: site.ru
в зависимости от того что для вас оптимальнее.
Вопрос: Когда планируется своевременное соблюдение директивы Host: в robots.txt? Если сайт индексируется как www.site.ru, когда указано Host: site.ru уже после того, как robots.txt был размещен 1–2 недели, то при этом сайт с www и без www не склеивается более 1–2 месяца и в Яндексе существуют одновременно 2 копии частично пересекающихся сайтов (один 550 страниц, другой 150 страниц, при этом 50 страниц одинаковых). Прокомментируйте, пожалуйста, проблемы с работой «зеркальщика».
Ответ: Расширение стандарта robots.txt, введенное Яндексом, директива Host - это не команда считать зеркалами два любых сайта, это указание, какой сайт из группы, определенных автоматически как зеркала, считать главным. Следовательно, когда сайты будут идентифицированы как зеркала, директива Host сработает.
HTML-тег
Робот Яндекса поддерживает тег noindex, который запрещает роботу Яндекса индексировать заданные (служебные) участки текста. В начале служебного фрагмента ставится , и Яндекс не будет индексировать данный участок текста.
В SEO мелочей не бывает. Иногда на продвижение сайта может оказать влияние всего лишь один небольшой файл — Robots.txt. Если вы хотите, чтобы ваш сайт зашел в индекс, чтобы поисковые роботы обошли нужные вам страницы, нужно прописать для них рекомендации.
«Разве это возможно?» , — спросите вы. Возможно. Для этого на вашем сайте должен быть файл robots.txt. Как правильно составить файл роботс , настроить и добавить на сайт – разбираемся в этой статье.
Что такое robots.txt и для чего нужен
Robots.txt – это обычный текстовый файл , который содержит в себе рекомендации для поисковых роботов: какие страницы нужно сканировать, а какие нет.
Важно: файл должен быть в кодировке UTF-8, иначе поисковые роботы могут его не воспринять.
Зайдет ли в индекс сайт, на котором не будет этого файла? Зайдет, но роботы могут «выхватить» те страницы, наличие которых в результатах поиска нежелательно: например, страницы входа, админпанель, личные страницы пользователей, сайты-зеркала и т.п. Все это считается «поисковым мусором»:
Если в результаты поиска попадёт личная информация, можете пострадать и вы, и сайт. Ещё один момент – без этого файла индексация сайта будет проходить дольше.
В файле Robots.txt можно задать три типа команд для поисковых пауков:
- сканирование запрещено;
- сканирование разрешено;
- сканирование разрешено частично.
Все это прописывается с помощью директив.
Как создать правильный файл Robots.txt для сайта
Файл Robots.txt можно создать просто в программе «Блокнот», которая по умолчанию есть на любом компьютере. Прописывание файла займет даже у новичка максимум полчаса времени (если знать команды).
Также можно использовать другие программы – Notepad, например. Есть и онлайн сервисы, которые могут сгенерировать файл автоматически. Например, такие как CY-PR.com или Mediasova .
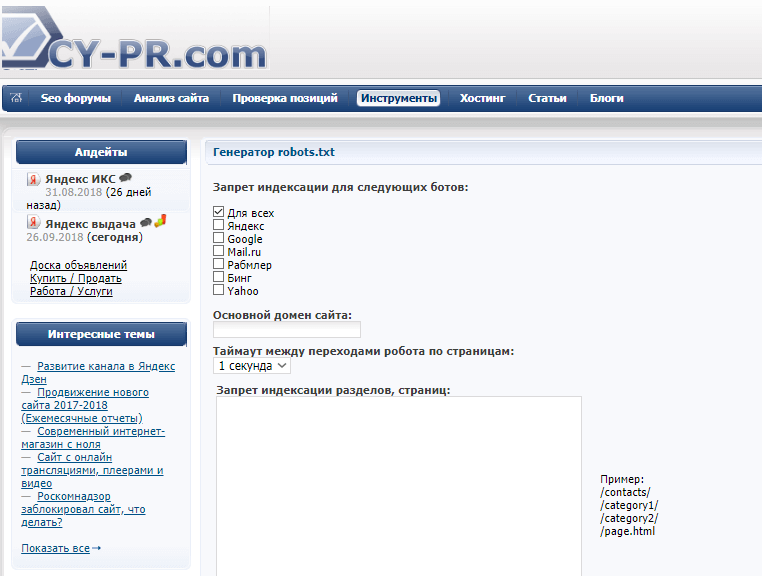
Вам просто нужно указать адрес своего сайта, для каких поисковых систем нужно задать правила, главное зеркало (с www или без). Дальше сервис всё сделает сам.
Лично я предпочитаю старый «дедовский» способ – прописать файл вручную в блокноте. Есть ещё и «ленивый способ» — озадачить этим своего разработчика 🙂 Но даже в таком случае вы должны проверить, правильно ли там всё прописано. Поэтому давайте разберемся, как составить этот самый файл, и где он должен находиться.
Готовый файл Robots.txt должен находиться в корневой папке сайта. Просто файл, без папки:

Хотите проверить, есть ли он на вашем сайте? Вбейте в адресную строку адрес: site.ru/robots.txt . Вам откроется вот такая страничка (если файл есть):

Файл состоит из нескольких блоков, отделённых отступом. В каждом блоке – рекомендации для поисковых роботов разных поисковых систем (плюс блок с общими правилами для всех), и отдельный блок со ссылками на карту сайта – Sitemap.
Внутри блока с правилами для одного поискового робота отступы делать не нужно.
Каждый блок начинается директивой User-agent.
После каждой директивы ставится знак «:» (двоеточие), пробел, после которого указывается значение (например, какую страницу закрыть от индексации).
Нужно указывать относительные адреса страниц, а не абсолютные. Относительные – это без «www.site.ru». Например, вам нужно запретить к индексации страницу www.site.ru/shop . Значит после двоеточия ставим пробел, слэш и «shop»:
Disallow: /shop.
Звездочка (*) обозначает любой набор символов.
Знак доллара ($) – конец строки.
Вы можете решить – зачем писать файл с нуля, если его можно открыть на любом сайте и просто скопировать себе?
Для каждого сайта нужно прописывать уникальные правила. Нужно учесть особенности CMS . Например, та же админпанель находится по адресу /wp-admin на движке WordPress, на другом адрес будет отличаться. То же самое с адресами отдельных страниц, с картой сайта и прочим.
Настройка файла Robots.txt: индексация, главное зеркало, диррективы
Как вы уже видели на скриншоте, первой идет директива User-agent. Она указывает, для какого поискового робота будут идти правила ниже.
User-agent: * — правила для всех поисковых роботов, то есть любой поисковой системы (Google, Yandex, Bing, Рамблер и т.п.).
User-agent: Googlebot – указывает на правила для поискового паука Google.
User-agent: Yandex – правила для поискового робота Яндекс.
Для какого поискового робота прописывать правила первым, нет никакой разницы. Но обычно сначала пишут рекомендации для всех роботов.
Disallow: Запрет на индексацию
Чтобы запретить индексацию сайта в целом или отдельных страниц, используется директива Disallow.
Например, вы можете полностью закрыть сайт от индексации (если ресурс находится на доработке, и вы не хотите, чтобы он попал в выдачу в таком состоянии). Для этого нужно прописать следующее:
User-agent: *
Disallow: /
Таким образом всем поисковым роботам запрещено индексировать контент на сайте.
А вот так можно открыть сайт для индексации:
User-agent: *
Disallow:
Потому проверьте, стоит ли слеш после директивы Disallow, если хотите закрыть сайт. Если хотите потом его открыть – не забудьте снять правило (а такое часто случается).
Чтобы закрыть от индексации отдельные страницы, нужно указать их адрес. Я уже писала, как это делается:
User-agent: *
Disallow: /wp-admin
Таким образом на сайте закрыли от сторонних взглядов админпанель.
Что нужно закрывать от индексации в обязательном порядке:
- административную панель;
- личные страницы пользователей;
- корзины;
- результаты поиска по сайту;
- страницы входа, регистрации, авторизации.
Можно закрыть от индексации и отдельные типы файлов. Допустим, у вас на сайте есть некоторые.pdf-файлы, индексация которых нежелательна. А поисковые роботы очень легко сканируют залитые на сайт файлы. Закрыть их от индексации можно следующим образом:
User-agent: *
Disallow: /*. pdf$
Как отрыть сайт для индексации
Даже при полностью закрытом от индексации сайте можно открыть роботам путь к определённым файлам или страницам. Допустим, вы переделываете сайт, но каталог с услугами остается нетронутым. Вы можете направить поисковых роботов туда, чтобы они продолжали индексировать раздел. Для этого используется директива Allow:
User-agent: *
Allow: /uslugi
Disallow: /
Главное зеркало сайта
До 20 марта 2018 года в файле robots.txt для поискового робота Яндекс нужно было указывать главное зеркало сайта через директиву Host. Сейчас этого делать не нужно – достаточно настроить постраничный 301-редирект .
Что такое главное зеркало? Это какой адрес вашего сайта является главным – с www или без. Если не настроить редирект, то оба сайта будут проиндексированы, то есть, будут дубли всех страниц.
Карта сайта: robots.txt sitemap
После того, как прописаны все директивы для роботов, необходимо указать путь к Sitemap. Карта сайта показывает роботам, что все URL, которые нужно проиндексировать, находятся по определённому адресу. Например:
Sitemap: site.ru/sitemap.xml
Когда робот будет обходить сайт, он будет видеть, какие изменения вносились в этот файл. В итоге новые страницы будут индексироваться быстрее.
Директива Clean-param
В 2009 году Яндекс ввел новую директиву – Clean-param. С ее помощью можно описать динамические параметры, которые не влияют на содержание страниц. Чаще всего данная директива используется на форумах. Тут возникает много мусора, например id сессии, параметры сортировки. Если прописать данную директиву, поисковый робот Яндекса не будет многократно загружать информацию, которая дублируется.
Прописать эту директиву можно в любом месте файла robots.txt.
Параметры, которые роботу не нужно учитывать, перечисляются в первой части значения через знак &:
Clean-param: sid&sort /forum/viewforum.php
Эта директива позволяет избежать дублей страниц с динамическими адресами (которые содержат знак вопроса).
Директива Crawl-delay
Эта директива придёт на помощь тем, у кого слабый сервер.
Приход поискового робота – это дополнительная нагрузка на сервер. Если у вас высокая посещаемость сайта, то ресурс может попросту не выдержать и «лечь». В итоге робот получит сообщение об ошибке 5хх. Если такая ситуация будет повторяться постоянно, сайт может быть признан поисковой системой нерабочим.
Представьте, что вы работаете, и параллельно вам приходится постоянно отвечать на звонки. Ваша продуктивность в таком случае падает.
Так же и с сервером.
Вернемся к директиве. Crawl-delay позволяет задать задержку сканирования страниц сайта с целью снизить нагрузку на сервер. Другими словами, вы задаете период, через который будут загружаться страницы сайта. Указывается данный параметр в секундах, целым числом:
Файл robots.txt находится в корневом каталоге вашего сайта. Например, на сайте www.example.com адрес файла robots.txt будет выглядеть как www.example.com/robots.txt. Файл robots.txt представляет собой обычный текстовый файл, который соответствует стандарту исключений для роботов , и включает одно или несколько правил, каждое из которых запрещает или разрешает тому или иному поисковому роботу доступ к определенному пути на сайте.
Вот пример простого файла robots.txt с двумя правилами. Ниже приведены пояснения.
# Группа 1 User-agent: Googlebot Disallow: /nogooglebot/ # Группа 2 User-agent: * Allow: / Sitemap: http://www.example.com/sitemap.xml
Пояснения
- Агент пользователя с названием Googlebot не должен сканировать каталог http://example.com/nogooglebot/ и его подкаталоги.
- У всех остальных агентов пользователя есть доступ ко всему сайту (можно опустить, результат будет тем же, так как полный доступ предоставляется по умолчанию).
- Файл Sitemap этого сайта находится по адресу http://www.example.com/sitemap.xml.
Ниже представлено несколько советов по работе с файлами robots.txt. Мы рекомендуем вам изучить полный синтаксис этих файлов , так как используемые при их создании синтаксические правила являются неочевидными и вы должны разбираться в них.
Формат и расположение
Создать файл robots.txt можно почти в любом текстовом редакторе с поддержкой кодировки UTF-8. Не используйте текстовые процессоры, поскольку зачастую они сохраняют файлы в проприетарном формате и добавляют в них недопустимые символы, например фигурные кавычки, которые не распознаются поисковыми роботами.
При создании и тестировании файлов robots.txt используйте инструмент проверки . Он позволяет проанализировать синтаксис файла и узнать, как он будет функционировать на вашем сайте.
Правила в отношении формата и расположения файла
- Файл должен носить название robots.txt.
- На сайте должен быть только один такой файл.
- Файл robots.txt нужно разместить в корневом каталоге сайта. Например, чтобы контролировать сканирование всех страниц сайта http://www.example.com/ , файл robots.txt следует разместить по адресу http://www.example.com/robots.txt . Он не должен находиться в подкаталоге (например, по адресу http://example.com/pages/robots.txt ). В случае затруднений с доступом к корневому каталогу обратитесь к хостинг-провайдеру. Если у вас нет доступа к корневому каталогу сайта, используйте альтернативный метод блокировки, например метатеги .
- Файл robots.txt можно добавлять по адресам с субдоменами (например, http://website .example.com/robots.txt) или нестандартными портами (например, http://example.com:8181 /robots.txt).
- Комментарием считается любой текст после символа #.
Синтаксис
- Файл robots.txt должен представлять собой текстовый файл в кодировке UTF-8 (которая включает коды символов ASCII). Другие наборы символов использовать нельзя.
- Файл robots.txt состоит из групп .
- Каждая группа может содержать несколько правил , по одному на строку. Эти правила также называются директивами .
- Группа включает следующую информацию:
- К какому агенту пользователя применяются директивы группы.
- есть доступ .
- К каким каталогам или файлам у этого агента нет доступа .
- Инструкции групп считываются сверху вниз. Робот будет следовать правилам только одной группы с наиболее точно соответствующим ему агентом пользователя.
- По умолчанию предполагается , что если доступ к странице или каталогу не заблокирован правилом Disallow: , то агент пользователя может их обрабатывать.
- Правила чувствительны к регистру . Так, правило Disallow: /file.asp применимо к URL http://www.example.com/file.asp , но не к http://www.example.com/File.asp .
Директивы, которые используются в файлах robots.txt
- User-agent: Обязательная директива, в группе таких может быть несколько . Определяет, к какому поисковому роботу должны применяться правила. С такой строки начинается каждая группа. Большинство агентов пользователя, относящихся к роботам Google, можно найти в специальном списке и в базе данных роботов Интернета . Поддерживается подстановочный знак * для обозначения префикса, суффикса пути или всего пути. Используйте знак * , как показано в примере ниже, чтобы заблокировать доступ всем поисковым роботам (кроме роботов AdsBot , которых нужно указывать отдельно). Рекомендуем ознакомиться со списком роботов Google . Примеры: # Пример 1. Блокировка доступа только роботу Googlebot User-agent: Googlebot Disallow: / # Пример 2. Блокировка доступа роботам Googlebot и AdsBot User-agent: Googlebot User-agent: AdsBot-Google Disallow: / # Пример 3. Блокировка доступа всем роботам, за исключением AdsBot User-agent: * Disallow: /
- Disallow: . Указывает на каталог или страницу относительно корневого домена, которые нельзя сканировать агенту пользователя, определенному выше. Если это страница, должен быть указан полный путь к ней, как в адресной строке браузера. Если это каталог, путь к нему должен заканчиваться косой чертой (/). Поддерживается подстановочный знак * для обозначения префикса, суффикса пути или всего пути.
- Allow: По крайней мере одна директива Disallow: или Allow: должна быть в каждой группе . Указывает на каталог или страницу относительно корневого домена, которые можно сканировать агенту пользователя, определенному выше. Используется, для того чтобы отменить директиву Disallow и разрешить сканирование подкаталога или страницы в закрытом для сканирования каталоге. Если это страница, должен быть указан полный путь к ней, как в адресной строке браузера. Если это каталог, путь к нему должен заканчиваться косой чертой (/). Поддерживается подстановочный знак * для обозначения префикса, суффикса пути или всего пути.
- Sitemap: Необязательная директива, таких в файле может быть несколько или не быть совсем. Указывает на расположение файла Sitemap, используемого на этом сайте. URL должен быть полным. Google не обрабатывает и не проверяет варианты URL с префиксами http и https или с элементом www и без него. Файлы Sitemap сообщают Google, какой контент нужно сканировать и как отличить его от контента, который можно или нельзя сканировать. Пример: Sitemap: https://example.com/sitemap.xml Sitemap: http://www.example.com/sitemap.xml
Другие правила игнорируются.
Ещё один пример
Файл robots.txt состоит из групп. Каждая из них начинается со строки User-agent , определяющей робота, который должен следовать правилам. Ниже приведен пример файла с двумя группами и с поясняющими комментариями к обеим.
# Блокировать доступ робота Googlebot к каталогам example.com/directory1/... и example.com/directory2/... # но разрешить доступ к каталогу directory2/subdirectory1/... # Доступ ко всем остальным каталогам разрешен по умолчанию. User-agent: googlebot Disallow: /directory1/ Disallow: /directory2/ Allow: /directory2/subdirectory1/ # Блокировать доступ ко всему сайту другой поисковой системе. User-agent: anothercrawler Disallow: /
Полный синтаксис файла robots.txt
Полный синтаксис описан в этой статье . Рекомендуем вам ознакомиться с ней, так как в синтаксисе файла robots.txt есть некоторые важные нюансы.
Полезные правила
Вот несколько распространенных правил для файла robots.txt:
| Правило | Пример |
|---|---|
| Запрет сканирования всего сайта. Следует учесть, что в некоторых случаях URL сайта могут присутствовать в индексе, даже если они не были просканированы. Обратите внимание, что это правило не относится к роботам AdsBot , которых нужно указывать отдельно. | User-agent: * Disallow: / |
| Чтобы запретить сканирование каталога и всего его содержания , поставьте после названия каталога косую черту. Не используйте файл robots.txt для защиты конфиденциальной информации! Для этих целей следует применять аутентификацию. URL, сканирование которых запрещено файлом robots.txt, могут быть проиндексированы, а содержание файла robots.txt может просмотреть любой пользователь, и таким образом узнать местоположение файлов с конфиденциальной информацией. | User-agent: * Disallow: /calendar/ Disallow: /junk/ |
| Чтобы разрешить сканирование только для одного поискового робота | User-agent: Googlebot-news Allow: / User-agent: * Disallow: / |
| Чтобы разрешить сканирование для всех поисковых роботов, за исключением одного | User-agent: Unnecessarybot Disallow: / User-agent: * Allow: / |
|
Чтобы запретить сканирование отдельной страницы , укажите эту страницу после косой черты. |
User-agent: * Disallow: /private_file.html |
|
Чтобы скрыть определенное изображение от робота Google Картинок |
User-agent: Googlebot-Image Disallow: /images/dogs.jpg |
|
Чтобы скрыть все изображения с вашего сайта от робота Google Картинок |
User-agent: Googlebot-Image Disallow: / |
|
Чтобы запретить сканирование всех файлов определенного типа (в данном случае GIF) |
User-agent: Googlebot Disallow: /*.gif$ |
|
Чтобы заблокировать определенные страницы сайта, но продолжать на них показ объявлений AdSense , используйте правило Disallow для всех роботов, за исключением Mediapartners-Google. В результате этот робот сможет получить доступ к удаленным из результатов поиска страницам, чтобы подобрать объявления для показа тому или иному пользователю. |
User-agent: * Disallow: / User-agent: Mediapartners-Google Allow: / |
| Чтобы указать URL, который заканчивается на определенном фрагменте , применяйте символ $ . Например, для URL, заканчивающихся на.xls , используйте следующий код: | User-agent: Googlebot Disallow: /*.xls$ |
Эта информация оказалась полезной?
Как можно улучшить эту статью?


